
基础
我们先来通过手动进行git的底层操作来理解git的工作原理
git内置三种对象
- blob(big large object),用于保存内容
- tree,用于标识树结构
- commit,用于保存每次提交
从创建对象到commit
新建一个空目录
mkdir /tmp/git-learn
进入该目录,执行git status,会得到一个报错
fatal: not a git repository (or any of the parent directories): .git
大意就是当前目录并不是一个git仓库,一个git仓库必要的两个组成部分:
.git/objects目录用于存储各种对象- 一个对象命名系统——references
创建两个目录
mkdir -p .git/objects
mkdir .git/refs
另外,git分支命名在refs/heads/下,并且需要一个HEAD文件告诉git从哪里开始
mkdir .git/refs/heads
echo "ref: refs/heads/fuckyou" > .git/HEAD
再次执行git status
On branch fuckyou
No commits yet
nothing to commit (create/copy files and use "git add" to track)
可以看到仓库已经起来了,而且git显示当前分支为fuckyou,这个是通过读取.git/HEAD实现的
下面我们创建一个对象
echo "mom is not home!" | git hash-object -w --stdin
上面的命令会返回一个SHA-1值,并在objects目录下创建文件:
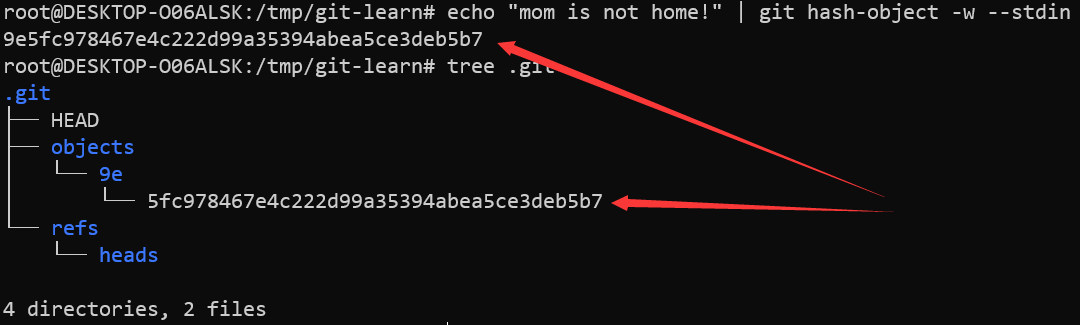
其中objects下的目录由之前返回的SHA-1值的前两个字符命名,剩下的字符作为文件名,这样是为了加快检索速度(查找次数相较直接使用SHA-1值作为文件名降低了256倍)
我们可以使用git cat-file -t SHA-1和git cat-file -p SHA-1来查看对象类型和内容
# git cat-file -t 9e5fc978467e4c222d99a35394abea5ce3deb5b7
blob
# git cat-file -p 9e5fc978467e4c222d99a35394abea5ce3deb5b7
mom is not home!
但是如果我们现在执行git status,我们会发现没有任何变化,因为没有任何被git追踪的文件
git是通过index文件获取该信息的,因此我们需要执行下面的命令来告知git
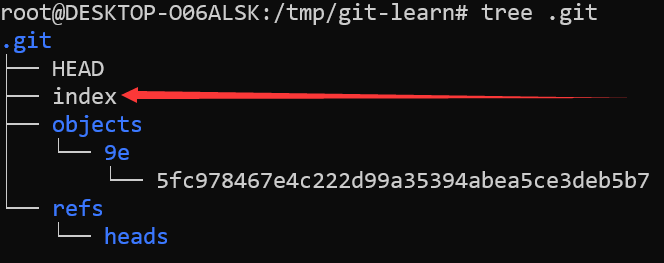
git update-index --add --cacheinfo 100644 9e5fc978467e4c222d99a35394abea5ce3deb5b7 pussy.txt
上面的100644是git定义的元数据描述,参考git/index-format.txt at master · git/git · GitHub
这条命令会创建出.git/index文件
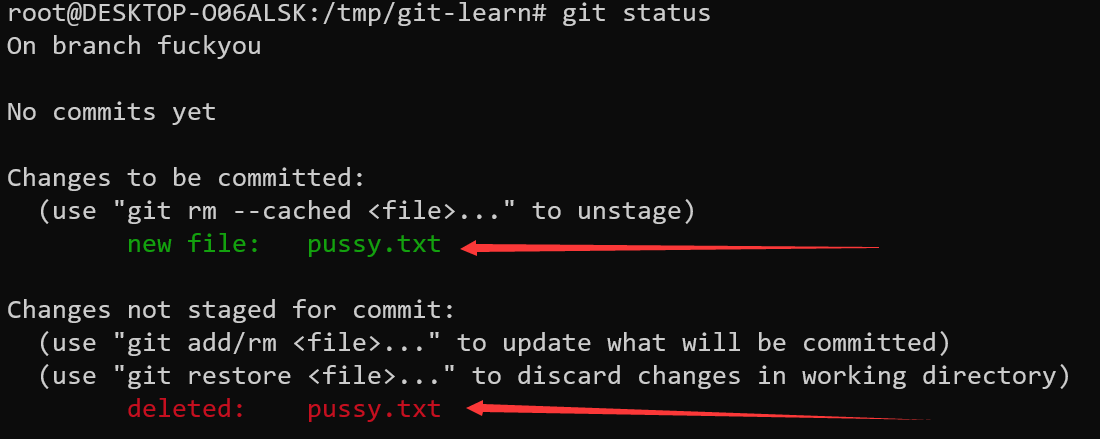
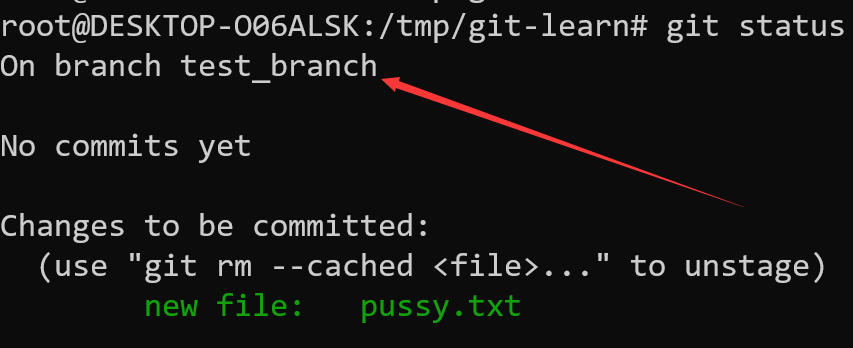
此时我们发现了有趣的事情,git显示pussy.txt已经被追踪(绿色),但是同时又显示该文件被删除掉了(红色)
绿色是因为我们已经把信息写到了index中,红色是因为工作目录并不存在pussy.txt这个文件
git cat-file -p 9e5fc978467e4c222d99a35394abea5ce3deb5b7 > pussy.txt
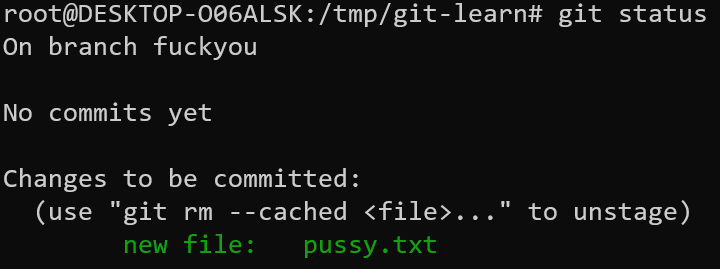
好了,现在我们可以commit了,其实commit也是一个指针,它指向一个tree,因此我们需要先创建一个tree
git write-tree
上面的命令返回一个SHA-1值,我们可以看一下它的内容
# git cat-file -t 6d3bccf2a1660dcb2edd4a1d857430d3afdfd018
tree
# git cat-file -p 6d3bccf2a1660dcb2edd4a1d857430d3afdfd018
100644 blob 9e5fc978467e4c222d99a35394abea5ce3deb5b7 pussy.txt
可以看到它保存了pussy.txt的信息
git commit-tree 6d3bccf2a1660dcb2edd4a1d857430d3afdfd018 -m "commit to fuckyou"
我们看一下commit对象的内容
# git cat-file -t 33ce52386bdd577d12fa44daab7c60bfe59d356d
commit
# git cat-file -p 33ce52386bdd577d12fa44daab7c60bfe59d356d
tree 6d3bccf2a1660dcb2edd4a1d857430d3afdfd018
author Your Name <you@example.com> 1623955420 -0700
committer Your Name <you@example.com> 1623955420 -0700
commit to fuckyou
可以看到,它保存了tree以及committer的名字、邮箱以及说明信息
其实通过上面的说明,xdm大致应该能捋出来git的这几个对象的关系,其实就是下面这张图
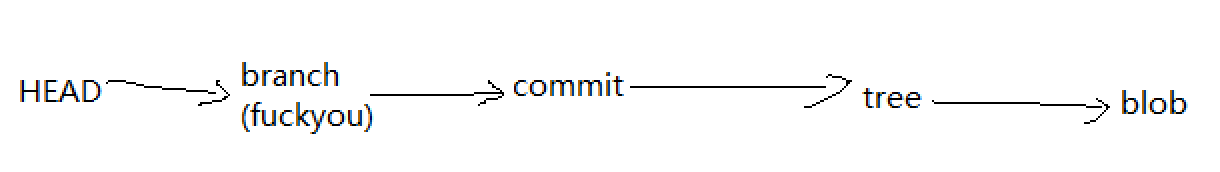
现在我们再看git status,它还是说我们没有commit
这是因为我们的branch没有指向我们刚才的commit,直接将commit的SHA-1值写到以分支命名的文件中即可
echo 33ce52386bdd577d12fa44daab7c60bfe59d356d > .git/refs/heads/fuckyou
成功commit
# git status
On branch fuckyou
nothing to commit, working tree clean
# git log
commit 33ce52386bdd577d12fa44daab7c60bfe59d356d (HEAD -> fuckyou)
Author: Your Name <you@example.com>
Date: Thu Jun 17 11:43:40 2021 -0700
commit to fuckyou
切换分支
echo 33ce52386bdd577d12fa44daab7c60bfe59d356d > .git/refs/heads/test_branch
上面的命令创建出了新的分支test_branch,并将分支指向之前的那一次commit
修改.git/HEAD文件来切换分支
echo "ref: refs/heads/test_branch" > .git/HEAD

切换完成!
在新分支中进行提交
我们进行之前的创建和提交操作,不再赘述
# echo "just sister and brother" | git hash-object -w --stdin
9868cccd41c6f92f5e5686f4f6402e2bab966c71
# git cat-file -p 9868cccd41c6f92f5e5686f4f6402e2bab966c71 > dick.txt
# git update-index --add --cacheinfo 100644 9868cccd41c6f92f5e5686f4f6402e2bab966c71 dick.txt
# git write-tree
f5c2b44457b2b8efec70920736a6ac7e6c625b58
# git commit-tree f5c2b44457b2b8efec70920736a6ac7e6c625b58 -m "commit to test_branch"
d2ffbc5d12b816d98e1e5a770dd9f15081904358
最后再将我们的分支指向commit就行了
echo d2ffbc5d12b816d98e1e5a770dd9f15081904358 > .git/refs/heads/test_branch

.git泄露原理
不管web服务器上的代码是是被push上去的还是从其他仓库pull下来的,只要.git目录可以不受限制的访问,就有可能完整还原所有的文件
使用gin解析.git/index文件,可以获取所有文件的路径
python3 -m pip install gin
gin .git/index
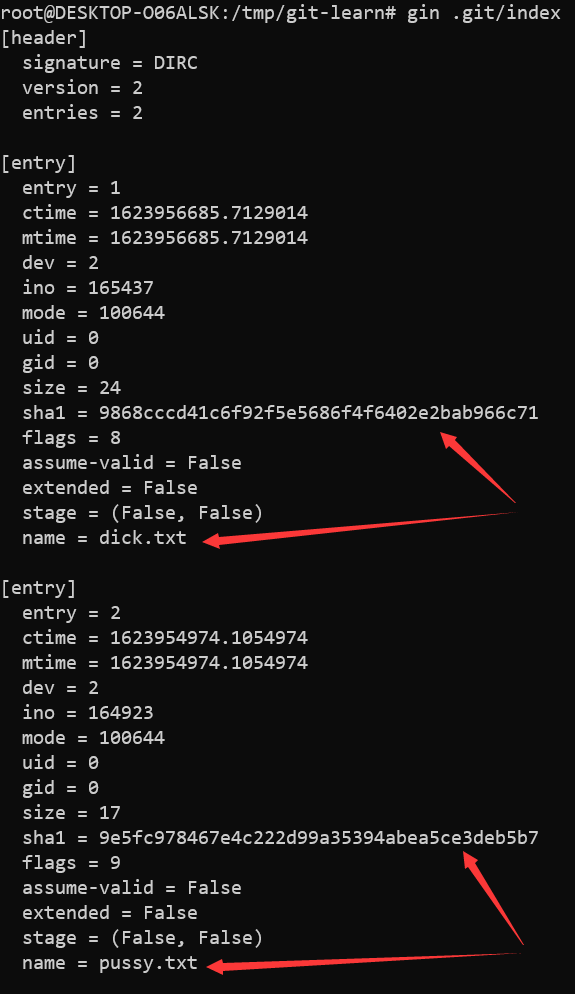
通过SHA-1值,我们可以在objects目录中找到对应的文件
然后解压该文件即可还原原来的内容
import zlib
filename = '.git/objects/e2/7bb34b0807ebf1b91bb66a4c147430cde4f08f'
compressed_contents = open(filename, 'rb').read()
decompressed_contents = zlib.decompress(compressed_contents)
print decompressed_contents

objects目录下找不到对应文件
git并不会一直把文件存储在objects目录下面
举个例子,我们有一个12MB的文件,它被保存在.git/objects目录下,后来该文件被修改了一次,修改内容是在文件最后加了一个!
那么我们就相当于存了两个几乎一模一样的文件在磁盘中,他们两个占了24MB的空间,这是极大的浪费,当我们的项目逐渐增大时,继续使用这种方式对文件内容进行保存是非常低效的方式
为了解决这个问题,git会周期性地对objects下的文件进行pack,这个被称作GC,被pack的文件会从objects中移除
gc的思想就是将文件保存为基文件和delta,delta就是一个描述文件,它描述了如何对基文件进行操作来生成新的文件
比如我们刚才新增一个!的情景,就可以分为一个12MB的基文件和一个小的可以忽略不计的delta
gc完成后,会在.git/objects/pack下生成两个文件,一个.idx和一个pack文件
在这种情况下,再按照之前的查找方式是无法恢复源文件的
而且00git中并没有任何文件保存了pack文件名相关信息,因此,只要无法进行目录遍历且目标仓库进行了gc操作,就没办法还原所有的文件
解析git的pack文件
虽然对于不存在目录便利的.git泄露来说,无从得知pack文件的文件名,但是对于存在目录遍历的情况,我们还是可以还原出原始文件内容的,下面就看一下如何解析pack文件
本来我是想看一下pack文件解析的原理的,但是后来转念一想,完全没有必要,TortoiseGit它不香嘛
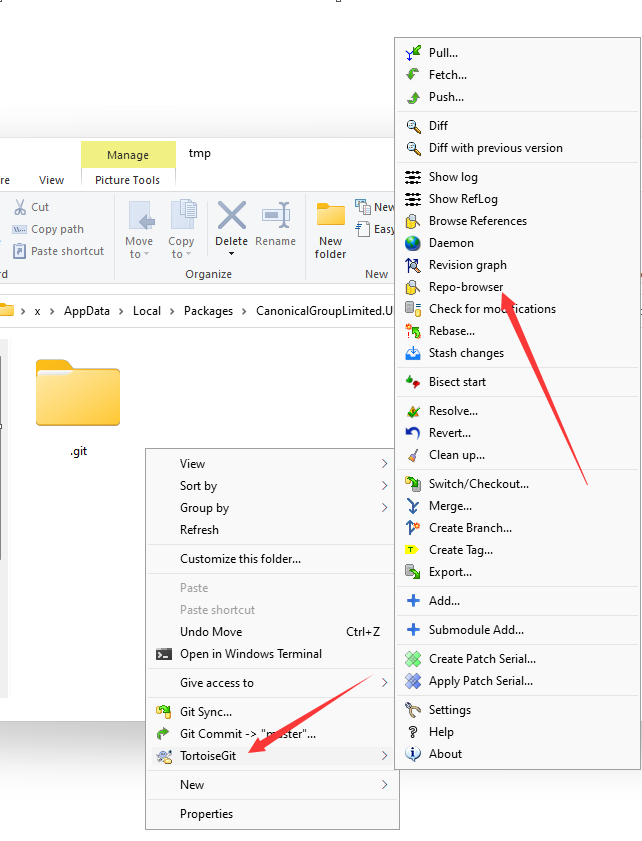
不存在目录遍历的我们就不说了,对于存在目录遍历的.git泄露,可以先使用wget下载到本地,然后直接使用TortoiseGit打开
wget -c -r -l inf -np -L http://1.1.1.1/.git/
Tortoise使用方法如下,可以浏览完整的git仓库中的文件
references:
- A Visual Guide to Git Internals — Objects, Branches, and How to Create a Repo From Scratch (freecodecamp.org)
- Packfiles - Git 內部原理 - Pro Git 繁體中文版 (iissnan.com)
- Git - git-pack-objects Documentation (git-scm.com)
- Unpacking Git packfiles (recurse.com)
- Reading git objects — Curious git (matthew-brett.github.io)