
前言
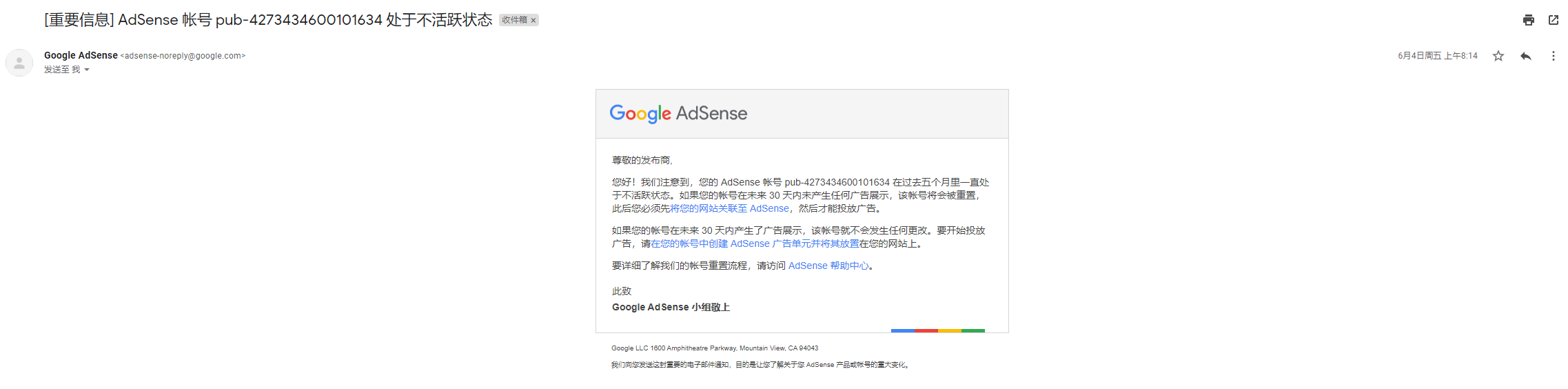
刚才在弄CDN的时候因为忘记密码,所以用google邮箱收了一下邮件,意外的发现自己的GoogleAdSense竟然通过了!
Yes!!!!
以前的都被驳回了,这次竟然成功了,而且是在1月份就通过了,我本来以为都没戏了,所以很久没看,辛亏今天发现了,不然再过几天就被重置了
赶紧发篇文章,希望网站点击量能蒸蒸日上!!!!
正文
之前在公众号上发过csdn图床的脚本
后来发现服务器的空间越来越少了,其中占用空间最大的莫过于图片了,因此就想着把这个脚本利用起来,而碰巧最新版本的typora支持自定义图片上传脚本
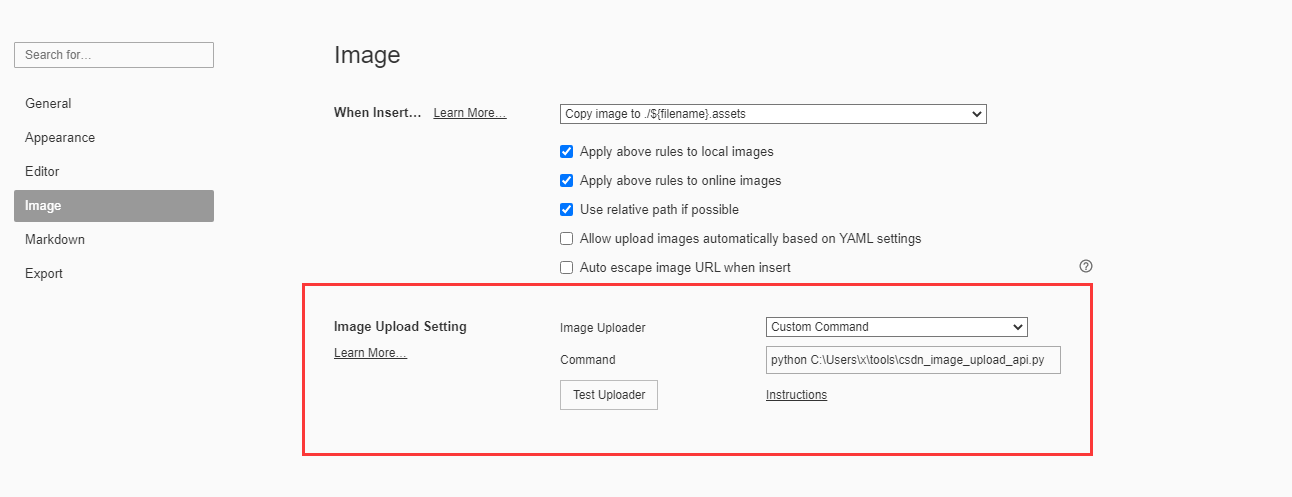
我填的命令是
python C:\Users\x\tools\csdn_image_upload_api.py
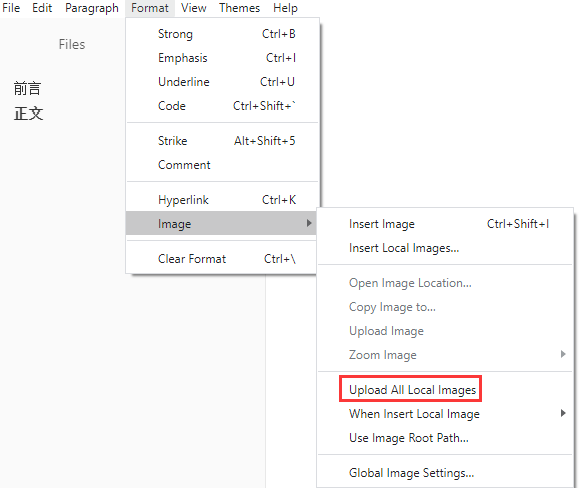
这个脚本就是根据之前的脚本进行了一下修改,首先我们需要修改让其支持多参数,因为Typora有一个上传全部本地图片的选项,该选项会将当前文档中所有的图片路径作为参数传递给我们的脚本
参数的处理
for item in sys.argv[1:]:
pic_path= item
pic_path = pic_path.replace("\\\\", "\\")
pic_path = urllib.parse.unquote(pic_path)
从第二个参数开始(第一个是脚本本身)逐个进行上传,由于typora传过来的参数中\进行过转义,因此需要将\\替换成\,另外中文字符进行了URL编码,因此还需要再进行一次解码
另外,windows命令行下接受的参数个数是有限制的,因此在使用Typora进行文档编辑时最好是时不时地上传一下本地图片
本地文件路径和图片url的映射
为了预防csdn哪天把我给ban了,或者官方对这个图片上传API进行了更严格的限制,我在上传文件的同时将本地文件和上传之后获得的URL进行了一个映射,并保存在对应文件的assets目录中的map.map文件中
图片上传完成后生成的map文件内容如下:

我单独写了一个脚本进行URL至本地文件的转换脚本,可以一次性的处理所有的md文档
import sys
import os
# f = open("c:\\1.txt","r", encoding="utf-8")
# lines = f.readlines()
# for line in lines
mylisadict = {}
for root,dirs,files in os.walk(r"C:\Users\x\AppData\Local\Packages\CanonicalGroupLimited.UbuntuonWindows_79rhkp1fndgsc\LocalState\rootfs\home\x\wochinijiamile\content"):
for dir in dirs:
# print(dir)
pathhdir = os.path.join(root,dir)
my_file = pathhdir +'\\map.map'
if os.path.isfile(my_file):
f = open(my_file,"r", encoding="utf-8")
lines = f.readlines()
for line in lines:
mylist = line.strip().split(',')
mylisadict[mylist[1]] = mylist[0]
f.close()
for root,dirs,files in os.walk(r"C:\Users\x\AppData\Local\Packages\CanonicalGroupLimited.UbuntuonWindows_79rhkp1fndgsc\LocalState\rootfs\home\x\wochinijiamile\content"):
for file in files:
if ".md" in file:
fuckfaile = os.path.join(root,file)
print(fuckfaile)
fff = open(fuckfaile,"r", encoding="utf-8")
lines = fff.readlines()
data = '
'.join([line.replace('\n', '') for line in lines])
for key,values in mylisadict.items():
data = data.replace(key, values)
data = data.replace('
', '\n')
fff.close()
fisssn = open(fuckfaile, "wt", encoding="utf-8")
fisssn.write(data)
fisssn.close()
将第9行和第22行的路径修改为md文件的路径即可
当然,不出意外的话,这个脚本是用不着的,最好永远都不要用上
图床脚本
除了上面提到的修改,最后对返回的json字符串的正则匹配也进行了小的改动,因为我发现gif文件回来的路径有点不太一样,因此单独匹配了一下
完整脚本下载地址:
安装依赖:
python.exe -m pip install requests
python.exe -m pip install filetype
python.exe -m pip install requests-toolbelt
大家在使用的时候需要根据自己的环境手动进行一些修改,比如第92行的代码就有我硬编码进去的字符串,XDM在用的时候需要进行更改
如果有任何问题,请在下方评论或者联系我邮箱
2023-06-09 更新
csdn中间更换过一次图片上传策略,后来又调整了,直接不让未授权网站直接在自己的网页中加载他们的图片了,所以用csdn作为网站的图床已经不合适了,改为使用github作为图床,反正我的网站在国内访问本来就很慢,所以我也不在乎访问github快还是慢了
github图床代码:
# -*- coding: utf-8 -*-
import os
import hashlib
import hmac
from base64 import b64decode,b64encode
import random
import requests
import http.cookiejar as cookielib
from urllib.parse import urlparse
import sys,os
#from get_all_article import get_all
import re
import urllib.parse
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
import json
import sys
import filetype
import requests
from requests_toolbelt import MultipartEncoder
import json
import requests
import base64
from github import Github
import random
import string
from sys import platform
motherslash =""
g = Github('替换为你自己的GitHub API Token')
if "win32" == platform:
motherslash="\\"
else:
motherslash ="/"
def generate_random_string(length):
"""Generate a random string of a given length."""
letters = string.ascii_letters
return ''.join(random.choice(letters) for i in range(length))
def uploadFile(filePath, file_name):
repo = g.get_repo('wqreytuk'+"/"+'img_repo')
try:
contents = repo.get_contents(filePath.split(motherslash)[-1], ref="main")
except Exception as e :
# 如果这个文件不存在就会抛出异常,那么我们就可以创建文件了
with open(filePath, "rb") as binaryFile:
encoded_string = base64.b64encode(binaryFile.read())
repo.create_file(file_name, "commit message", base64.b64decode(encoded_string.decode('utf-8')), branch="main")
return 'https://raw.githubusercontent.com/wqreytuk/img_repo/main/'+file_name
def createUuid():
text = ""
char_list = []
for c in range(97,97+6):
char_list.append(chr(c))
for c in range(49,58):
char_list.append(chr(c))
for i in "xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx":
if i == "4":
text += "4"
elif i == "-":
text += "-"
else:
text += random.choice(char_list)
return text
def get_sign(uuid,url):
s = urlparse(url)
ekey = "9znpamsyl2c7cdrr9sas0le9vbc3r6ba".encode()
to_enc = f"POST\n*/*\n\nmultipart/form-data; boundary=----WebKitFormBoundaryJ2aGzfsg35YqeT7X\n\nx-ca-key:203803574\nx-ca-nonce:{uuid}\n/blog-console-api/v3/upload/img?shuiyin=2".encode()
# print(to_enc)
sign = b64encode(hmac.new(ekey, to_enc, digestmod=hashlib.sha256).digest()).decode()
return sign
def check_size():
pic_size = os.path.getsize(pic_path)
if pic_size > 5242880:
return False
else:
return True
def check_type():
extension = os.path.splitext(pic_path)[1].lower()
if extension == ".jpeg" or extension == ".jpg":
return True
if extension == ".gif":
return True
if extension == ".png":
return True
if extension == ".bmp":
return True
if extension == ".webp":
return True
return False
# my_open = open("C:\\Users\\x\\AppData\\Local\\Packages\\CanonicalGroupLimited.UbuntuonWindows_79rhkp1fndgsc\\LocalState\\rootfs\\tmp\\12.png.txt", 'w', encoding="utf-8")
# for item in sys.argv[1:]:
# my_open.write(item)
# my_open.write('\n')
# my_open.close()
if len(sys.argv) < 2:
sys.exit(0)
mappath=''
temppath = sys.argv[1].replace("\\\\", "\\")
temppath = urllib.parse.unquote(temppath)
temppath = temppath.split('\\')
for ppppath in temppath[:-1]:
ppppath+='\\'
mappath += ppppath
for item in sys.argv[1:]:
pic_path= item
#print(pic_path)
pic_path = pic_path.replace("\\\\", "\\")
pic_path = urllib.parse.unquote(pic_path)
sopurce_str = pic_path.split('content\\')
sopurce_str = sopurce_str[1].replace('\\','/')
#print(sopurce_str)
#print(sopurce_str)
filename = os.path.split(pic_path)[-1]
mime = filetype.guess(pic_path).mime
if not check_size():
print("5M")
else:
if not check_type():
print("jpg .gif .png .jpeg .bmp .webp")
else:
http_proxy = "http://127.0.0.1:8080"
image_path =pic_path
proxyDict = {
"https" : http_proxy
}
image_duffix = image_path.split('.')[-1]
headers = {}
headers['Cookie'] = 'uuid_tt_dd=10_7112015950-1639885058827-362577; dc_session_id=10_1639885058827.570610; c_segment=1; c_page_id=default; dc_sid=eed914f227de263f524cb4cfbda6dc0b; SESSION=c4915425-05f5-4090-8a58-c0fa78df6173; c_pref=https://www.csdn.net/; c_ref=https://mp.csdn.net/; ssxmod_itna=iuDtAKBK7KDK4BcDeqC4jOxREG8yttY=dD/ItGDnqD=GFDK40oYHwKYDO8RN83bWRy415UnBexmTR=iuEC8R1f0oIPnxx0aDbqGkdROrQGGmxBYDQxAYDGDDPODj4ibDY tg9vxWKDwDB=DmqG2BkNDA4Dj8qww8qGEDA3DG8=Dmf=MBbi/YeDSF0UoIA=DjqGgDBLqW6h9DDUak6xDbEmuDeiDtqD9tmtXYeDHnOGb844CRxLPi9GCROhqIi3YUYhdtADj1R KmSIKIDv30OO32fCxD; ssxmod_itna2=iuDtAKBK7KDK4BcDeqC4jOxREG8yttY=G9YvFbDmxGXhKaGaIzITkx8g3UO/ Py4zubDliQhXnWey2x2W6DBth7I mYiOZAWYxoDwcGPGcDYFqxD; UserName=ma_de_hao_mei_le; UserInfo=d27ca33ac3ed424eaf249b73b44e56a8; UserToken=d27ca33ac3ed424eaf249b73b44e56a8; UserNick=ma_de_hao_mei_le; AU=F0F; UN=ma_de_hao_mei_le; BT=1639885104824; p_uid=U010000; c_first_ref=passport.gitcode.net; c_first_page=https://mp.csdn.net/; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1639885066,1639885087; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac={"islogin":{"value":"1","scope":1},"isonline":{"value":"1","scope":1},"isvip":{"value":"0","scope":1},"uid_":{"value":"ma_de_hao_mei_le","scope":1}}; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7112015950-1639885058827-362577!5744*1*ma_de_hao_mei_le; log_Id_click=3; log_Id_view=4; dc_tos=r4cffy; log_Id_pv=5; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1639885104'
headers['Connection'] ='close'
headers['Accept'] ="""application/json, text/javascript, */*; q=0.01"""
headers['x-image-app'] = 'direct_blog'
headers['x-image-dir'] = 'direct'
headers['Content-Type'] = """application/json"""
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
headers['x-image-suffix'] = image_duffix
headers['Origin'] = 'https://editor.csdn.net'
headers['Sec-Fetch-Site'] = 'same-site'
headers['Sec-Fetch-Mode'] = 'cors'
headers['Sec-Fetch-Dest'] = 'empty'
headers['Referer'] = 'https://editor.csdn.net/'
headers['Accept-Encoding'] = "gzip, deflate"
headers['Accept-Language'] = 'zh-CN,zh;q=0.9'
response = requests.get("https://imgservice.csdn.net/direct/v1.0/image/upload?watermark=&type=blog&rtype=markdown", headers=headers)
jd = json.dumps(response.text)
jjd = json.loads(jd)
# print(jjd)
key = jjd.split('"filePath":"')[1].split('.')[0] + '.'+image_duffix
policy = jjd.split('"policy":"')[1].split('","signature":"')[0]
OSSAccessKeyId = jjd.split('"accessId":"')[1].split('","policy":')[0]
success_action_status='200'
signature = jjd.split(',"signature":"')[1].split('","dir"')[0]
callback= jjd.split('"callbackUrl":"')[1].split('","filePath"')[0]
multipart_data = MultipartEncoder(
fields={
# a file upload field
# plain text fields
'key':key,
'policy':policy,
'OSSAccessKeyId':OSSAccessKeyId,
'success_action_status':success_action_status,
'signature':signature,
'callback':callback,
'file': ('image.'+image_duffix, open(image_path, 'rb'), 'image/png'),
}
)
response = requests.post('https://csdn-img-blog.oss-cn-beijing.aliyuncs.com', data=multipart_data,
headers={'Content-Type': multipart_data.content_type})
#/*,proxies=proxyDict,verify=False*/)
#asdasdasd=response.text.split('"imageUrl":"')[1].split('"},"msg"')[0].split('",')[0]
#file_path = r"C:\Users\x\AppData\Roaming\Tencent\QQMusic\QQMusicCache\QQMusicPicture\黄龄_龄·EP_4.jpg"
file_name = generate_random_string(10) + ".jpg"
asdasdasd = uploadFile(pic_path, file_name)
print(asdasdasd)
mmmmmmmmmmmmmmmmmmmpaht = mappath+'map.map'
my_open = open(mmmmmmmmmmmmmmmmmmmpaht, 'a', encoding="utf-8")
my_open.write(sopurce_str+','+asdasdasd+'\n')
my_open.close()
在Line33填入你自己的Github API Token,然后分别将脚本中的字符串wqreytuk和img_repo替换为你的Github用户名和用于存放图片的仓库名称